

위의 그림은 VLM의 간단한 예시로써, 개와 고양이 이미지와 몇 가지 프롬프트를 전달하여 입력 이미지에 대한 가장 가능성 있는 프롬프트를 얻어내는 내용입니다. 이런 예측을 하려면 모델은 입력 이미지와 텍스트 프롬프트를 모두 이해해야 합니다. 이것이 VLM의 장점입니다. VLM은 "Vision-Language Model"의 약자입니다.
VLM은 컴퓨터 비전과 자연어 처리를 결합한 인공지능 모델로 시각적 정보(예: 이미지, 비디오)와 텍스트 데이터를 함께 처리할 수 있는 능력을 갖추고 있습니다. 즉 비전-언어 모델(VLM)은 이미지와 자연어 텍스트를 모두 처리할 수 있는 인공지능 모델입니다.
이러한 모델들은 이미지 설명 생성, 이미지-텍스트 검색, 멀티 모달 학습 등 다양한 응용 분야에서 사용됩니다.
결국 생성형 AI도 궁극적으로는 로봇과의 결합이 필요한데 이때 VLM(Vision-Language Model)은 중요한 역할을 합니다. 실제 환경에서 시각적 정보를 이해하고 그에 맞는 행동을 해야 하는 로봇에게 VLM은 시각적 정보를 처리하고 텍스트로 주어진 명령이나 설명과 결합하여 상황을 정확하게 이해하도록 도와줍니다.
VLM은 텍스트와 시각적 데이터를 동시에 학습하는 멀티 모달 학습을 기반으로 하기 때문에, 로봇이 다양한 환경과 상황에 더 잘 적응할 수 있도록 합니다. 예를 들어 새로운 물체를 처음 보더라도 텍스트 설명과 함께 학습한 정보에 기반해 그 물체를 이해할 수 있습니다. 이는 로봇이 예측 불가능한 상황에서도 적절하게 대응할 수 있는 능력을 제공하게 됩니다.
VLM의 활용은 아마존 홈페이지에 있는 아래 내용을 이해하면 쉬울 것 같습니다.
2021년 이후 시각 언어 모델(VLM)에 대한 관심이 증가하면서 대조적 언어-이미지 사전 훈련(CLIP) 및 부트스트래핑 언어-이미지 사전 훈련(BLIP)과 같은 모델이 출시되었습니다.
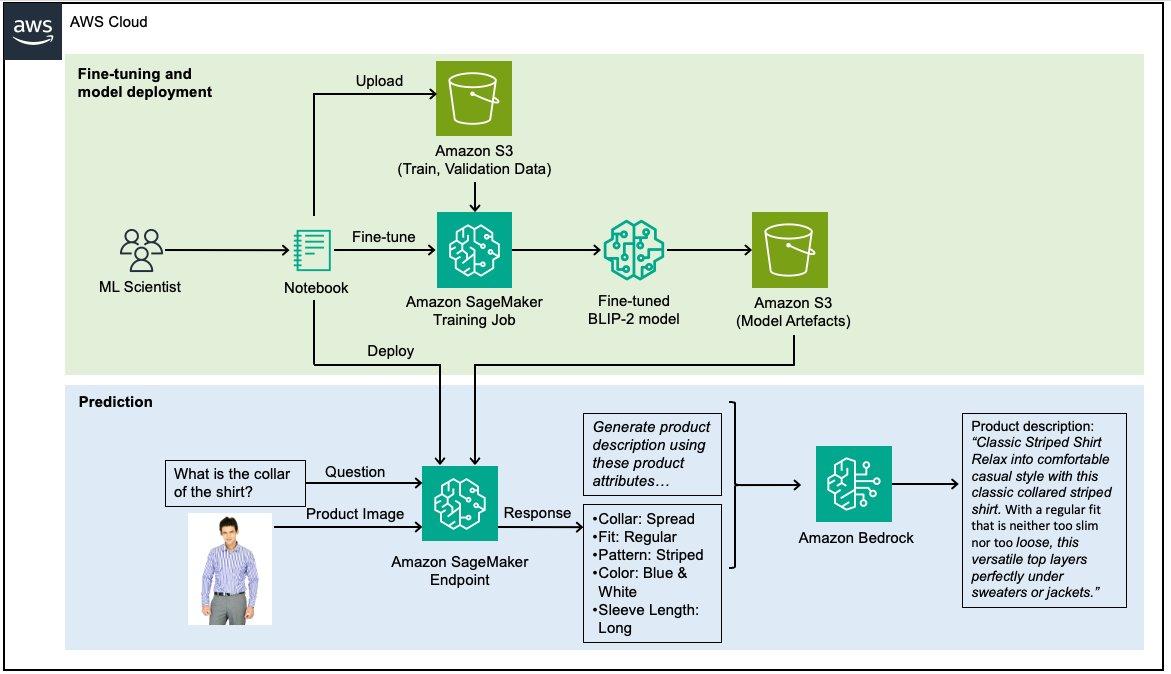
위의 내용은 BLIP 모델을 파인 튜닝(fine tuning)으로 활용한 예입니다. SageMaker와 Amazon Bedrock을 사용하여 비전 언어 모델을 미세 조정하여 패션 제품 설명 생성하는 응용 사례입니다.
"이 셔츠의 칼라는 무엇인가요? (What is the collar of the shirt?)"라고 이미지와 프롬프트를 주고 물으면, 결과로써 "편안한 캐주얼 스타일로 빠져들게 해주는 이 클래식한 칼라 스트라이프 셔츠. 슬림하지도 너무 헐겁지도 않은 레귤러 핏으로, 이 다용도 탑은 스웨터나 재킷 아래에 완벽하게 어울립니다. (Classic Striped Shirt Relax into comfortable casual style with this classic collared striped shirt. With a regular fit that is neither too slim nor too loose, this versatile top layers perfectly under sweaters or jackets.)"라고 아주 멋진 답을 주게 합니다.
이와 같은 방식으로 응용하면 다양한 산업분야에서 활용할 수 있습니다.
- 디지털 마케팅: 타깃팅 광고에서 특정 객체가 포함된 이미지를 정확하게 찾아내어 관련된 텍스트 광고를 제공함으로써 광고 효과를 높입니다.
- 교육: 복잡한 개념을 설명하기 위해 시각적 자료와 텍스트 설명을 통합하는 데 유용하여 학습자들의 이해를 돕습니다.
- 디자인 및 예술: 창의적인 콘텐츠 생성, 예술 작품 제작 등에 활용되어 창작자들의 상상력을 자극합니다.
- 광고 및 마케팅: 맞춤형 이미지 생성으로 광고 캠페인을 강화할 수 있어 브랜드 이미지를 효과적으로 전달합니다.
- 전자상거래: 제품 이미지와 연관된 텍스트 설명을 자동으로 생성해 상점의 상품 페이지 관리 효율을 높이고 고객의 구매 전환율을 개선합니다.
- 로봇 산업: 로봇이 시각적 데이터를 분석해 주변 환경을 이해하고 그에 맞는 행동을 할 수 있도록 도와 로봇의 자율성을 높입니다.
- 엔터테인먼트: 사용자에게 맞춤형 콘텐츠를 제공함으로써 더욱 몰입감 있는 경험을 제공해 사용자 만족도를 높입니다.
VLM 관련 기술의 벤치마크 동향을 한국전자통신연구원에서 발간하여 URL 링크를 걸어 둡니다. 내용을 요약하면 대략 이런 내용입니다.
"""
언어 기반 로봇 작업 계획과 제어 기술은 로봇이 사람과 자연스럽게 상호작용하고 다양한 환경에서 복잡한 작업을 수행할 수 있게 하는 핵심 기술입니다. 이를 위해서는 로봇의 실세계 이해, 작업 계획 수립 능력 그리고 사물 조작 능력을 체계적이고 객관적으로 평가할 수 있는 벤치마크가 필수적입니다.
현재 OpenEQA, PASTURE, ALFRED, EgoPlan-Bench, BC-Z Robot, Ravens, LoHoRavens, VIMA-Bench, Calvin, Language-Table 등 다양한 벤치마크들이 개발되어 이러한 기술의 학습과 평가에 활용되고 있습니다.
향후에는 보다 현실적이고 도전적인 작업을 포함하는 벤치마크의 개발과 최신 인공지능 기술을 로봇 제어에 활용하는 연구가 활발히 이루어질 것으로 전망됩니다.
"""
URL : 정보통신기획평가원 정기간행물
(혹시 다운로드가 안 되면 직접 해당 홈페이지 정기간행물 코너로 직접 들어가시면 됩니다.)
https://www.itfind.or.kr/WZIN/jugidong/2144/file1699719717329084407-2144(2024.08.07)-26.pdf
'인공지능(AI) > 인공지능 동향' 카테고리의 다른 글
| [2024년 10월21일] 가트너, 2025년 10대 전략 기술 트렌드 발표 (10) | 2024.10.31 |
|---|---|
| [2024년 9월] 에델만(Edelman) 2024 AI 리포트 (9) | 2024.10.22 |
| [2024년 8월 자료] 동향 파악용 자료 소개 (AI 반도체 기술 및 산업 동향) (3) | 2024.09.09 |
| [2024년 8월8일] 동향 파악용 자료 소개(생성형 인공지능의 현재와 전망 외) (1) | 2024.08.08 |
| 생성형 인공지능(AI)을 넘어서 : Contextual AI의 최신 동향 (0) | 2024.08.03 |