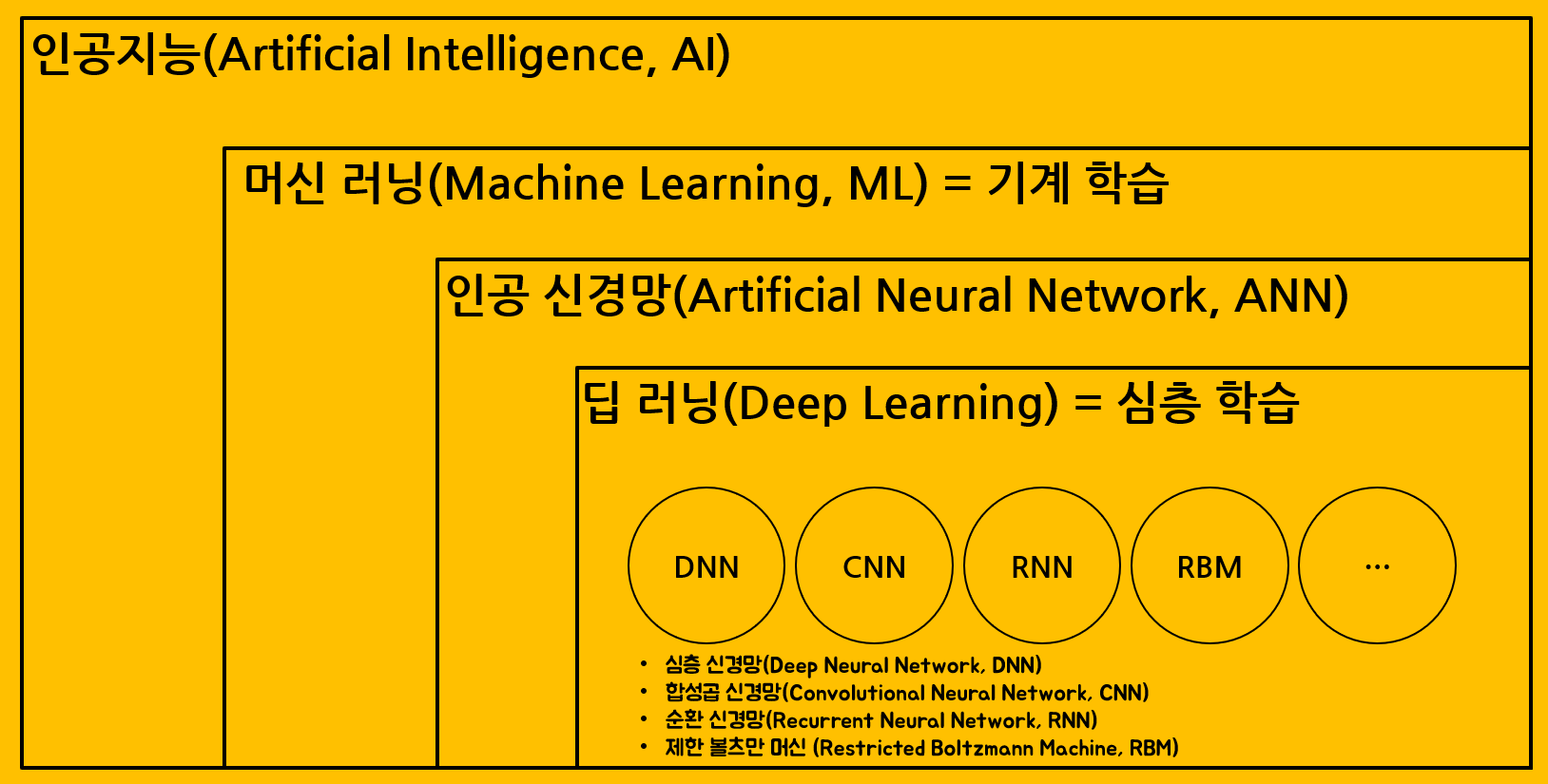
인간의 지능적인 특성 중에는 학습이 있습니다. 학습은 배워서 익히는 것입니다. 그럼 어떻게 배울까요? 우리는 경험을 통해 배웁니다. 그래서 우리는 여러 경험을 통해 학습을 얻어내고 그 학습은 다음 행동에 영향을 주도록 변화해왔습니다. 이렇게 우리가 학습하는 특성을 컴퓨터인 기계에 접목한 것이 머신 러닝이고, 딥 러닝입니다. 전통적인 프로그램 방식에서는 프로그래머인 사람이 일일 명시적으로 알고리즘을 설계하고, 코딩해서 컴퓨터가 주어진 입력에 대한 출력을 갖도록 해왔습니다. 그러나 인공지능 기법이 도입되면, 컴퓨터인 기계는 주어진 입력 데이터와 출력 데이터로(혹은 입력 데이터로만) 기계가 자동적으로 명시적인 프로그래밍 없이 학습하여 그 결과 규칙을 적용하게 됩니다. 아래 그림을 보면 쉽게 이해될 것 입니다...